 Your new post is loading...
Your new post is loading...

|
Scooped by
nrip
|
Moore's law enables great progress, but often it's the underlying algorithms that drive computer science forward. Everybody loves to talk about Moore’s law—which states that transistor counts on a microprocessor double about every two years—when talking about speed and productivity improvements in computing. But the gains that come from new algorithms may exceed ones from hardware improvements. Algorithmic improvements make more efficient use of existing resources and allow computers to do a task faster, cheaper, or both. Think of how easy the smaller MP3 format made music storage and transfer. That compression was because of an algorithm. The study cites Google’s PageRank, Uber’s routing algorithm, and Netflix video compression as examples. Many of these algorithms come from publicly available sources—research papers and other publications. This “algorithmic commons”—like the digital commons of open source software and publicly available information—helps all programmers produce better software. read the entire unedited article at https://stackoverflow.blog/2021/03/24/forget-moores-law-algorithms-drive-technology-forward/
|
|
Scooped by
nrip
|
Everyone can learn how to code. Computer science theories will teach you how to program you will get the following benefits if you learn computer science fundamentals before programming. Theories motivate you to write highly optimized code. Performance is still a crucial factor in software development regardless of modern hardware. if we are working close to the hardware or our product is being used by millions of end-users — we still need to write highly optimized code for modern computers. If we need to write optimized code, we need to use the right data structures, fast algorithms, and optimized memory models. This knowledge comes from computer science theories such as data structures, asymptotic analysis of algorithms, and CPU architecture. Theories explain the coder vs. programmer role. According to the majority’s opinion, the meaning of the word coding literally gives the same meaning as the word programming. Let me explain a hidden fact. Coding is not programming — coders and programmers don’t do the same thing. A coder can write codes in a high-level programming language for a compiler or an interpreter. You don’t need to understand how a computer works or any of its internals to write code. On the other hand, a programmer also writes code but understands the internals. A programmer can build fully functional software products by minimizing errors. In other words, coding is a subset of the programming field. Theories will help you find your expertise. In the software industry, there are two choices: We can either become a jack of all trades or become a master in a preferred field. In fact, developers can master more than one closely connected field as well. For example, my favorite fields are cloud computing and software architecture. Nowadays, the majority of junior developers start their careers with frontend engineering because of the current trend. After several years, we often hear these kinds of developers say that they don’t work with the things they like. Theories make you a better problem solver. Software development is not straightforward all the time. Developers often meet problems that need reliable and efficient solutions. A software engineering solution’s triumph depends on the software development team’s skills and expertise. For example, a team can introduce an instant inefficient solution. Meanwhile, another team can solve the same problem with an efficient solution. Computer science theories help developers come up with efficient and smart solutions. Conclusion Computer science theories are not required to enter the software development field, but those theories give you more perks. The same scenario happens with the programming languages as well. Undoubtedly, developers can start programming with any modern programming language.
|
|
Scooped by
nrip
|
Use a Language Your Company Can Support That in a nutshell is the most important criteria A natural corollary is that if you want to introduce a new programming language to a company, it is your responsibility to convince the business of the benefit of the language. You need to generate organizational support for the language before you go ahead and start using it. This can be difficult, it can be uncomfortable, and you could be told no. But without that organizational support, your new service is dead in the water. read more at https://sookocheff.com/post/engineering-management/the-most-important-criteria-for-choosing-a-programming-language/
|
|
Scooped by
nrip
|
As a programmer or developer, the importance of creating secure applications cannot be overstated. Software security deals with the management of malicious attacks by identifying potential vulnerabilities in software and taking the necessary precautions to guard against them. Software can never be 100% secure because a developer can overlook a bug, create new bugs in an attempt to fix existing cases, or create new vulnerabilities through updates. However, there’re two key practices that all software developers can employ to ensure that they create secure software --- - writing secure code in the first place, and
- efficiently testing your code.
Software Security Is a Crucial Skill For All Developers Developing good software is synonymous with ensuring that your software can withstand any malicious attack. This is only achievable through the writing of secure code, the continual testing of an application, and maintaining control of who has access to your data. read more at https://www.makeuseof.com/software-security-skill-all-programmers-should-have/
|
|
Scooped by
nrip
|
This is an opinion article about the state of affairs in the software engineering field. It discusses the real challenge and the real duty of a programmer. It divides programmers into four categories: Intelligent, Bandits, Helpless and Stupid with two additional categories of Naive and Ignorant. It talks about how a programmer must be familiar with a particular domain is not only able to code but actually to create solutions. And it touches on the failure of agile software development. Failure of software projects defined as a miss of deadlines, budget overrun, missed functionality and malfunction is prevalent in the software industry. A lot has been written about the reasons for this situation, blaming unrealistic project goals, inaccurate estimates of needed resources, badly defined requirements, poor reporting, unmanaged risks, poor communication, immature technology, sloppy development practices, poor project management, stakeholder politics or commercial pressure. Most of these put weight on the management side of the development process, properly identifying it as a cause of these failures. In my opinion, which is based on years of observation, there is another factor of this misery almost totally overlooked or intentionally omitted – programmers themselves. “Smart” Programmers The common belief among society in general and among programmer society as well is that “programmers are smart”, that they recruit from the most intelligent part of the society. I believe that this is based on a false assumption that programming a machine is difficult. I dare to disagree with this assumption as in reality, writing code is no more difficult than writing a proper culinary recipe The Nature of Challenge Coding is not a challenge. In fact, code is the last thing anybody is willing to pay for (though, ironically, it is the most important thing that gets produced in the end). The real challenge, and the real duty of a programmer, is solving problems that customers face, most likely with code but not necessarily. These problems are usually only partially “technical”, often sociological, often complex, often wicked. As problem complexity grows, the required effort, intelligence, knowledge, and dedication to solve it grow as well, sometimes exponentially. Recognizing complexity, confining it and minimizing it is the ultimate goal of a programmer. This raises the bar so high that an average person might fail to present the sufficient personal qualities required for the job, and turn out to be relatively stupid. As David Parnas states: “I have heard people proudly claim that they have built lots of large complex systems. I try to remind them that the job could have been done by a small simple system if they had spent more time on "front-end" design. Large size and complexity should not be viewed as a goal.” The 4 + 2 Model It is necessary to unambiguously define stupidity in the context of programming. “A stupid programmer is the one that puts complexity to a software product that negatively impacts other programmers, customers or a whole company while achieving no gain from this fact and even possibly negatively impacting oneself”. By putting complexity, I mean either failing to reduce the inherent complexity of the problem being solved with software, by using so-called “brute force” solutions or actually introducing of accidental (usually technical) complexity, that could be avoided if more thought and care was given to the solution. By negative impact, I understand the increased workload, reduced efficiency, and higher cost. The Great Misunderstanding Programmers are technology-oriented. They get attracted to computing because of their technological bias. Their job though is not to write code as they often think, their job is not even creating software. Their job is to solve customers’ problems and software is just one of the means to do it. Sadly, seldom do they manage to understand this. A Bitter Pill I found this enlightening quote from David Parnas: The most often-overlooked risk in software engineering is ‘incompetent programmers’. There are estimates that the number of programmers needed in the U.S. exceeds 200,000. This is entirely misleading. It is not a quantity problem; we have a quality problem. One bad programmer can easily create two new jobs a year. Hiring more bad programmers will just increase our perceived need for them. If we had more good programmers, and could easily identify them, we would need fewer, not more.” If the project is late, it is better to fire bad programmers than to hire more of them. At least, they will not get in the way of good ones. one of the best articles I have read on CodeProject ever. I read it 4 times over the past month and made every lead in the mid-level software management team read it too... read more at https://www.codeproject.com/Articles/5061258/The-Psychological-Reasons-for-Software-Project-Fai
|
|
Scooped by
nrip
|
Providing clear steps to reproduce an issue is a benefit for everyone When I’ve had to contact a company’s technical support through a form, I provide a ridiculously detailed description of what the issue is, when it happens, the specific troubleshooting that narrows it down, and (if it is allowed by the form) screenshots. I suspect the people on the other end aren’t used to that, because I know it is not what happens most of the time when people submit issues to me. What’s the benefit of an effective bug report? There are two sides to this, one is the efficiency of the interaction between the bug reporter and the (hopeful) bug fixer and the other is the actual likelihood that the issue will ever be fixed. Why do we need “repro steps”? The first part of fixing a problem is to make sure you understand it and can see it in action. If you can’t see the problem happen consistently, you can’t be sure you’ve fixed it. This is not a software development concept; it is true with nearly everything. If someone tells me the faucet is dripping, I’m going to want to see the drip happening before I try to fix it… then when I look and see it not dripping, I can feel confident that I resolved the problem. Is it possible to provide too much information? I’d rather have too much detail than too little, but I also feel that the bug reporter shouldn’t be expected to try to track down every possible variable or to try to fix the problem. Human Nature and Incomplete Issues I mentioned two sides to this, the efficiency of interaction and the likelihood an issue will be fixed. If you assume someone will ask for all the missing info, even if it takes a lot longer, then the only benefit to a complete bug report is efficiency. In reality though, developers are human, and when they see an incomplete issue where it could take many back-and-forth conversations to get the details they need, they will avoid it in favor of one that they can pick up and work on right now with no delay. Your issue, which could be more important than anything else in the queue, could end up being ignored because it is unclear. A detailed bug report, with clear repro steps, is a win for everyone. read this entire unedited super post at https://www.duncanmackenzie.net/blog/creating-an-effective-bug-report/
|
|
Scooped by
nrip
|
Style guides for Google-originated open-source projects “Style” covers a lot of ground, from “use camelCase for variable names” to “never use global variables” to “never use exceptions.” This project (google/styleguide) links to the style guidelines we use for Google code. If you are modifying a project that originated at Google, you may be pointed to this page to see the style guides that apply to that project. This project holds the Python Style Guide, HTML/CSS Style Guide, JavaScript Style Guide, TypeScript Style Guide, AngularJS Style Guide, C++ Style Guide, C# Style Guide, Swift Style Guide, Objective-C Style Guide, Java Style Guide, R Style Guide, Shell Style Guide, Common Lisp Style Guide, and Vimscript Style Guide. If your project requires that you create a new XML document format, the XML Document Format Style Guide may be helpful. In addition to actual style rules, it also contains advice on designing your own vs. adapting an existing format, on XML instance document formatting, and on elements vs. attributes.
|
|
Scooped by
nrip
|
|
|
Scooped by
nrip
|
Python creator Guido van Rossum reveals the strengths and weaknesses of one of the world's most popular programming languages. mobile app development is one of the key growth fields that Python hasn't gained any traction in, despite it dominating in machine learning with libraries like NumPy and Google's TensorFlow, as well as backend services automation. Python isn't exactly boxed into high-end hardware, but that's where it's gravitated to and it's been left out of mobile and the browser, even if it's popular on the backend of these services, he said. Why? Python simply guzzles too much memory and energy from hardware, he said. For similar reasons, he said Python probably doesn't have a future in the browser despite WebAssembly, a standard that is helping make more powerful applications on websites. Mobile app development in Python is a "bit of a sore point", said van Rossum in a recent video Q&A for Microsoft Reactor. "It would be nice if mobile apps could be written in Python. There are actually a few people working on that but CPython has 30 years of history where it's been built for an environment that is a workstation, a desktop or a server and it expects that kind of environment and the users expect that kind of environment," he said. "The people who have managed to cross-compile CPython to run on an Android tablet or even on iOS, they find that it eats up a lot of resources," he said. "Compared to what the mobile operating systems expect, Python is big and slow. It uses a lot of battery charge, so if you're coding in Python you would probably very quickly run down your battery and quickly run out of memory," he said. "Python is a pretty popular language [at the backend]. At Google I worked on projects that were sort of built on Python, although most Google stuff wasn't. At Dropbox, the whole Dropbox server is built on Python. On the other hand, if you look at what runs in the browser, that's the world of JavaScript and unless it translates to JavaScript, you can't run it," van Rossum said. "I don't mind so much different languages have to have different goals i mean nobody is asking Rust when you can write Rust in the browser; at least that wouldn't seem a useful sort of target for Rust either. Python should focus on the application areas where it's good and for the web that's the backend and for scientific data processing." watch the Microsoft Q&A with him at https://www.youtube.com/watch?v=aYbNh3NS7jA read the original article at https://www.zdnet.com/article/python-programming-why-it-hasnt-taken-off-in-the-browser-or-mobile-according-to-its-creator/
|
|
Scooped by
nrip
|
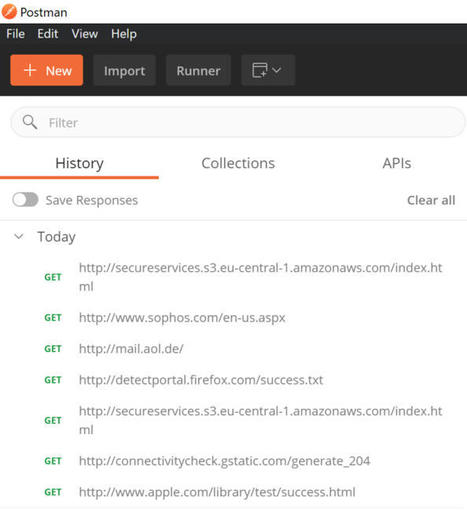
This post will show you how you can combine the native proxy function of your iOS device to route to Postman. Where you can then start tracing the API calls made by a native mobile application. Makes sense so far? Cool! Let’s get to it! - have postman installed. So click on the icon at the top right that allows you to capture requests. Toggle the “Capture Requests” flag to on, and you are good to go here. - open up the command shell, and type “ipconfig” to find out your local IP address ; Note it down - pick up your mobile device. Go to your WIFI settings and select “Configure Proxy” ; - enter the IP you just noted down as “Server” and type 5555 for the “Port” ; - Once you press save, you will immediately see some URLs passing by on the Postman history … - Now open up the app you want to trace… and do whatever you want to trace… � see the details with screenshots at https://kvaes.wordpress.com/2021/05/05/how-to-reverse-engineer-3th-party-mobile-api-calls-with-postman/
|
|
Scooped by
nrip
|
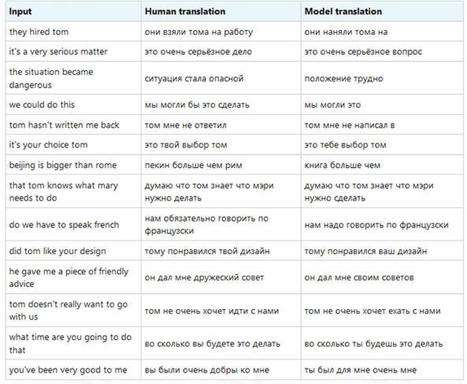
Google Translate works so well, it often seems like magic. But it’s not magic — it’s deep learning! In this series of articles, we’ll show you how to use deep learning to create an automatic translation system. This series can be viewed as a step-by-step tutorial that helps you understand and build a neuronal machine translation. This series assumes that you are familiar with the concepts of machine learning: model training, supervised learning, neural networks, as well as artificial neurons, layers, and backpropagation. In the previous article, we installed all the tools required to develop an automatic translation system, and defined the development workflow. In this article, we’ll go ahead and build our AI language translation system. We’ll need to write very few lines of code because, for most of the logic, we’ll use Keras-based pre-formatted templates. If you'd like to see the final code we end up with, it's available in this Python notebook. read the article with the code here https://www.codeproject.com/Articles/5299748/Building-AI-Language-Translation-with-TensorFlow-a
|
|
Scooped by
nrip
|
Whatever business a company may be in, software plays an increasingly vital role, from managing inventory to interfacing with customers. Software developers, as a result, are in greater demand than ever, and that’s driving the push to automate some of the easier tasks that take up their time. Productivity tools like Eclipse and Visual Studio suggest snippets of code that developers can easily drop into their work as they write. These automated features are powered by sophisticated language models that have learned to read and write computer code after absorbing thousands of examples. But like other deep learning models trained on big datasets without explicit instructions, language models designed for code-processing have baked-in vulnerabilities. A new framework built by MIT and IBM researchers finds and fixes weaknesses in automated programming tools that leave them open to attack. It’s part of a broader effort to harness artificial intelligence to make automated programming tools smarter and more secure.
|
|
Scooped by
nrip
|
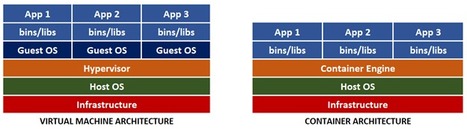
This article provides experienced developers with a comprehensive look at containerization: where it came from, how it works, and a look at the typical tools you'd use to build and deployed containerized cloud native apps. Here we: look at a brief history of how containerization started, explain what a modern container is, talk about how to build a container and copy an application you've written into it, explain why you'd want to push your container to a registry and how you can deploy straight from registries into production, and discuss deployment. Rise of the Modern Container Containerization took the IT industry by storm with the popularization of Docker. Containers were similar to VMs, but without the guest operating system (OS), leaving a much simpler package. The "works on my machine" excuses from developers are no longer an issue, as the application and its dependencies are all self-contained and shipped into the same unit called a container image. Images are ready-to-deploy copies of apps, while container instances created from those images usually run in a cloud platform such as Azure. The new architecture lacks the hypervisor since it is no longer needed. However, we still need to manage the new container, so the container engine concept was introduced. Containers are immutable, meaning that you can’t change a container image during its lifetime: you can't apply updates, patches, or configuration changes. If you must update your application, you should build a new image (which is essentially a changeset atop an existing container image) and redeploy it. Immutability makes container deployment easy and safe and ensures that deployed applications always work as expected, no matter where. Compared to the virtual machine, the new container is extremely lightweight and portable. Also, containers boot much faster. Due to their small size, containers help maximize use of the host OS and its resources. You can run Linux and Windows programs in Docker containers. The Docker platform runs natively on Linux and Windows, and Docker’s tools enable developers to build and run containers on Linux, Windows, and macOS. You can't use a container to run apps living on the local filesystem. However, you can access files outside a Docker container using bind mounts and volumes. They are similar, but bind mounts can point to any directory on the host computer and aren't managed by Docker directly. A Docker container accesses physical host hardware, like a GPU, on Linux but not on Windows. This is so because Docker on Linux runs on the kernel directly, while Docker on Windows works in a virtual machine, as Windows doesn't have a Linux kernel to directly communicate with. read this entire introduction to containers at Code project https://www.codeproject.com/Articles/5298350/An-Introduction-to-Containerization
|
|
|
Scooped by
nrip
|
AutoDev: an AI-driven development framework, relegates human developers to the role of mere supervisors of AI doing software engineering. The authors have outlined—and successfully tested—a system of multiple AI agents interacting with each other as well as provided repositories to not only tackle complex software engineering tasks but also validate the outcomes on their own. In other words, instead of writing code, human developers would become spectators to the work of AI, interjecting whenever deemed necessary. It’s really more akin to a management role, where you work with a team of people, guiding them towards the goals set for a project.
|
|
Scooped by
nrip
|
“Don’t write clever code.” Why not? “Because it’s hard to understand.” People who say this think of clever code such as Duff’s Device:
Duff's Device
send(to, from, count) register short *to, *from; register count; { register n = (count + 7) / 8; switch (count % 8) { case 0: do { *to = *from++; case 7: *to = *from++; case 6: *to = *from++; case 5: *to = *from++; case 4: *to = *from++; case 3: *to = *from++; case 2: *to = *from++; case 1: *to = *from++; } while (--n > 0); } } This code is “clever” because it exploits knowledge about the language, in this case the peculiarities of fall-through. Clever code can also exploit knowledge about the operating environment or special topics like bit twiddling. Conventional wisdom says this clever code is “bad”. There’s a second kind of “clever code”: code which exploits knowledge about the problem. Consider sorting all 300+ million people in the US by birth date. The “simple” solution is to use quicksort, which has a “log₂ factor” of ~30. The “clever” solution is to exploit the fact that everybody in the US is under 120 years old and instead bucket sort with ~45000 buckets. That sorts the list in a single pass, which is an order of magnitude more efficient. This kind of clever code can also be easier to understand. Since you’re solving a simpler problem than the general case, you can write less code and make things clearer. This usually ends up being highly domain specific We talk about cleverness as if it’s Just Bad, such as “clever code is harder to debug”. That’s going too far. Cleverness can lead to faster, safer, even clearer code. I’m going to call this class of cleverness “insightful” to distinguish them. Issues with Insight Insights can make code faster, simpler, and safer. But it’s also fragile: insights only work because they exploit some property in the problem. If the problem changes, even slightly, the insightful solution might break down I’m drawn to this distinction (Insights vs Cleverness) because I feel like our discussions of “clever code” are too constrained. While “pure” cleverness is something we should discourage, “insightful” cleverness seems like something we should be approaching differently. It’s something that often is necessary to make things work and which can be better than the equivalent “boring” code. It’s important to note the use of insight as well as the contextual constraints that made use of insight possible and what happens if they change. We also should see how it affects our discussions about software. How does “this tool needs insight to use” relate to “this tool is hard to learn”? Are there different expectations of insight in different fields, or at different levels of expertise? Do certain coding approaches depend more on insight than others, and does that affect generalizability? Are there ways to teach insight? People get some baseline insight as they develop expertise in something, but I don’t know if you can teach insight on top of that. My gut says no, but I think I’m wrong here. read more at https://www.hillelwayne.com/post/cleverness/
|
|
Scooped by
nrip
|
Starting out as a software developer can be tough. In your first few years on the job, you’re likely to face a steep learning curve as you work on growing your coding skills and just learning your way around work in the tech industry. One way to help ease some of those challenges is finding a mentor — someone with more experience who can help teach and guide you as you establish yourself as a software developer What Is a Mentor? A mentor isn’t the same thing as a boss or a more experienced colleague you spend time with. A mentor is someone who is more experienced in a career field (like software development) who sets out specifically to form a relationship with someone less experienced. A mentor helps them learn important job skills and overcome common challenges in the field, but should also become a trusted advisor who can help set them on a path toward grother in all aspects of their life, both career and personal. A relationship with a mentor should be long-term. And while the less-experienced developer in the relationship will reap the most benefit, a mentor-mentee relationship should be fulfilling for both parties, helping them both grow in different ways. 5 Reasons Why Developers Need Mentors Teach You Coding Best Practices Show You Where You Can Improve Help You Find the Right Resources to Grow Offer You New Perspectives Help You Grow Personally read more at https://www.7pace.com/blog/every-developer-needs-a-mentor
|
|
Scooped by
nrip
|
Python is not the only option for programming machine learning applications. There’s a growing community of developers who are using JavaScript to run machine learning models. While JavaScript is not a replacement for the rich Python machine learning landscape (yet), there are several good reasons to have JavaScript machine learning skills. Here are four. Private machine learning Fast and customized ML models Easy integration of machine learning in web and mobile applications Server side JavaScript machine learning is maturing JavaScript for programming machine learning offers several advantages over Python and R, namely privacy, speed, and staying on the device. read more at https://venturebeat.com/2021/04/23/4-reasons-to-learn-machine-learning-with-javascript/
|
|
Scooped by
nrip
|
Traditionally, developers have created properties inside of JavaScript classes for any data that might be needed within an instance. This isn’t a problem for small pieces of data that are readily available inside of the constructor. However, if some data needs to be calculated before becoming available in the instance, you may not want to pay that cost upfront. It may not be efficient to perform a calculation upfront if you aren’t sure the property will be used. Fortunately, there are several ways to defer these operations until later. The on-demand property pattern The easiest way to optimize performing an expensive operation is to wait until the data is needed before doing the computation. For example, you could use an accessor property with a getter to do the computation on demand The messy lazy-loading property pattern Only performing the computation when the property is accessed is a good start. What you really need is to cache the information after that point and just use the cached version. But where do you cache that information for easy access? The easiest approach is to define a property with the same name and set its value to the computed data The only-own lazy-loading property pattern for classes If you have a use case where it’s important for the lazy-loaded property to always exist on the instance, then you can using Object.defineProperty() to create the property inside of the class constructor. It’s a little bit messier than the previous example, but it will ensure that the property only ever exists on the instance The lazy-loading property pattern for object literals If you are using an object literal instead of a class, the process is much simpler because getters defined on object literals are defined as enumerable own properties (not prototype properties) just like data properties. That means you can use the messy lazy-loading property pattern for classes without being messy Conclusion The ability to redefine object properties in JavaScript allows a unique opportunity to cache information that may be expensive to compute. By starting out with an accessor property that is redefined as a data property, you can defer computation until the first time a property is read and then cache the result for later use. This approach works both for classes and for object literals, and is a bit simpler in object literals because you don’t have to worry about your getter ending up on the prototype. One of the best ways to improve performance is to avoid doing the same work twice, so any time you can cache a result for use later, you’ll speed up your program. Techniques like the lazy-loading property pattern allow any property to become a caching layer to improve performance. read this post with more details and code examples at https://humanwhocodes.com/blog/2021/04/lazy-loading-property-pattern-javascript/
|
|
Scooped by
nrip
|
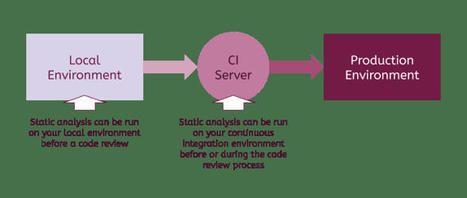
Static analysis is the practice of analyzing source code before it is running. In compiled programming languages, static analysis might be built into the compiler, but in dynamically interpreted languages like JavaScript, static analysis tools must be configured to run on the code sometime before it is deployed. Static analysis in JavaScript can drastically improve your code quality. Take a look at how so, some available tools and tips for implementing this practice. Because static analysis can be fully automated, it’s one of the best ways to improve the quality of your JavaScript code without investing developer time. But how exactly can static analysis help, and what tools are available to JavaScript developers? 1. Formatting and Styling Code The most common tools for static analysis in the JavaScript ecosystem—ESLint, JSHint, Prettier, Standard—are primarily used to ensure consistency in a team’s codebase. 2. Detecting Bugs and Errors While no substitute for testing, several static analysis tools can be used to catch likely errors before code is ever run. ESLint, PMD, Prettier and Standard are all good free tools that have rules for this kind of error detection. 3. Enforcing Best Practices You can enforce best practices automatically using static analysis. Prettier and Standard include opinionated rules about best practices, while ESLint and PMD are a bit more configurable. 4. Measuring Complexity If you want to catch increasing complexity or limit the cyclomatic complexity of your source code, Plato, ESLint or complexity-report are good static analysis tools for you. 5. Analyzing Security Risks While you can’t depend on static analysis alone to prevent security vulnerabilities, it’s certainly worth automating what you can. While some of the tools above indirectly improve security by decreasing likely bugs, LGTM is a security-focused tool that takes a novel approach Using the knowledge that common bugs are repeated across projects, LGTM scans thousands of large open-source projects to help you spot similar bugs in your codebase. This may lead to a lot of false alerts, but it might be worth trying in your project. 6. Auditing Third-Party Dependencies JavaScript applications tend to rely on many third-party libraries and frameworks. This makes development faster, but it puts a huge strain on teams that have to keep these third-party dependencies up to date. Fortunately, static analysis tools can help remind you when updates are required and even automatically manage this upgrade process. - Dependabot 7. Checking Types JavaScript applications can use type checking using tools like Flow or TypeScript to ensure consistent use of variable types. read the entire post at https://www.telerik.com/blogs/going-beyond-eslint-overview-static-analysis-javascript
|
|
Scooped by
nrip
|
Microsoft has announced that it's now possible to run graphical Linux apps in Windows 10 using the Windows Subsystem for Linux. This feature was first released to Windows Insiders. As this year's Build developer event kicks off, Microsoft has announced a major new feature for Windows 10 - the ability to run Linux apps with a GUI. This is a major expansion of the Windows Subsystem for Linux, which already lets you run command line-based Linux apps, and it means you can now use GUI apps without having to set up a traditional virtual machine with a Linux distribution. Interestingly, this feature has actually been in testing with Windows Insiders on the Dev channel since April, but it isn't coming through a typical Windows 10 feature update. It's just available now for existing versions of Windows 10 and you can start using it right away. read : https://www.neowin.net/news/you-can-now-run-linux-gui-apps-in-windows-10/
|
|
Scooped by
nrip
|
Understand more about the Web Audio API, an API that allows us to create and manage sounds in our browser very easily. Web Audio API Let’s start with the basics about the Web Audio API. This is how the API works: - The Web Audio API has a main audio context.
- Inside that audio context, we can handle and manage our audio operations. The audio operations are handled by audio nodes.
- We can have a lot of different audio nodes inside the same audio context, allowing us to create some nice things such as drum kits, synthesizers, etc.
Let’s create our first audio context using the Web Audio API and start to make some noise in our browser. This is how you can create an audio context: const audioContext = new (window .AudioContext || window .webkitAudioContext ); The audio context is an object that contains all stuff audio related. It’s not a good idea to have more than one audio context in your project—this can cause you a lot of trouble in the future. The Web Audio API has an interface called OscillatorNode. This interface represents a periodic waveform, pretty much a sine wave. Let’s use this interface to create some sound. Now that we have our audioContext const initiating the audio context, let’s create a new const called mySound, passing the audioContext const and calling the createOscillator method, like this: const mySound = audioContext .createOscillator(); We created our OscillatorNode, now we should start the mySound, like this: But, as you can see, it’s not playing anything in your browser. Why? We create our audioContext const initiating the audio context, but we didn’t pass any destination to it. We should always pass a property called destination to our audioContext const, otherwise, it won’t work. So, now, just use the mySound const, call a method called connect and pass our audioContext.destination, like this: mySound .connect(audioContext .destination ); Now we’re using the Web Audio API to very easily create noises in our browser. Properties The OscillatorNode has some properties, such as type. The type property specifies the type of waveform that we want our OscillatorNode to output. We can use 5 forms of output: sine (default), square, sawtooth, triangle and custom. To change the type of our OscillatorNode, all we must do is pass after the start() method a type to our mySound, like this: The OscillatorNode also has another property called frequency. We can use this property to represent the oscillation of our OscillatorNode in hertz. To change the oscillation of our OscillatorNode in hertz, we must call the frequency property, and call the setValueAtTime function. This function receives two arguments: the value in hertz and our audio context. We can use it like this: mySound .frequency .setValueAtTime(400, audioContext .currentTime ); By using the Web Audio API, we can manage audio pretty easily now in our browsers, but if you’re wanting to use this API to create something more difficult and powerful, you’ll probably need to use a library for it. read the entire article including the details on how to use Howler at https://www.telerik.com/blogs/understanding-web-audio-api
|
|
Scooped by
nrip
|
ONNX is an open format built to represent machine learning models. ONNX defines a common set of operators - the building blocks of machine learning and deep learning models - and a common file format to enable AI developers to use models with a variety of frameworks, tools, runtimes, and compilers. It was introduced in September 2017 by Microsoft and Facebook. ONNX breaks the dependence between frameworks and hardware architectures. It has very quickly emerged as the default standard for portability and interoperability between deep learning frameworks. Before ONNX, data scientists found it difficult to choose from a range of AI frameworks available. Developers may prefer a certain framework at the outset of the project, during the research and development stage, but may require a completely different set of features for production. Thus organizations are forced to resort to creative and often cumbersome workarounds, including translating models by hand. ONNX standard aims to bridge the gap and enable AI developers to switch between frameworks based on the project’s current stage. Currently, the models supported by ONNX are Caffe, Caffe2, Microsoft Cognitive toolkit, MXNET, PyTorch. ONNX also offers connectors for other standard libraries and frameworks. Two use cases where ONNX has been successfully adopted include: - TensorRT: NVIDIA’s platform for high performance deep learning inference. It utilises ONNX to support a wide range of deep learning frameworks.
- Qualcomm Snapdragon NPE: The Qualcomm neural processing engine (NPE) SDK adds support for neural network evaluation to mobile devices. While NPE directly supports only Caffe, Caffe 2 and TensorFlow frameworks, ONNX format helps in indirectly supporting a wider range of frameworks.
The ONNX standard helps by allowing the model to be trained in the preferred framework and then run it anywhere on the cloud. Models from frameworks, including TensorFlow, PyTorch, Keras, MATLAB, SparkML can be exported and converted to standard ONNX format. Once the model is in the ONNX format, it can run on different platforms and devices. ONNX Runtime is the inference engine for deploying ONNX models to production. The features include: - It is written in C++ and has C, Python, C#, and Java APIs to be used in various environments.
- It can be used on both cloud and edge and works equally well on Linux, Windows, and Mac.
- ONNX Runtime supports DNN and traditional machine learning. It can integrate with accelerators on different hardware platforms such as NVIDIA GPUs, Intel processors, and DirectML on Windows.
- ONNX Runtime offers extensive production-grade optimisation, testing, and other improvements
access the original unedited post at https://analyticsindiamag.com/onnx-standard-and-its-significance-for-data-scientists/ Access the ONNX website at https://onnx.ai/ Start using ONNX -> Access the Github repo at https://github.com/onnx/onnx
|
|
Scooped by
nrip
|
The author was applying for a program and a task was given to him was to build an ECR20 token in less than 48 hours. This was my first attempt at blockchain development and I didn’t know where to start from. I had knowledge of the cryptocurrency world from a user stand point but not as a developer. I searched around for materials to aid in my task but most were not up to date. This is an up-to-date write up on the steps I took while building this token to help others that are interested in building their own token. Step 1: Contract code Step 2: Create Ethereum wallet with MetaMask Step 3: Get Ropsten Ethers Step 4: Edit the contract code Step 5: Deploy Contract Code on Remix Step 6: Publish and Verify Contract Step 7: Add token to your wallet Congrats!!!
You’ve just created your token. read this excellently written starter at https://www.codementor.io/@vahiwe/building-your-own-ethereum-based-ecr20-token-in-less-than-an-hour-16f44bq67i
|
|
Scooped by
nrip
|
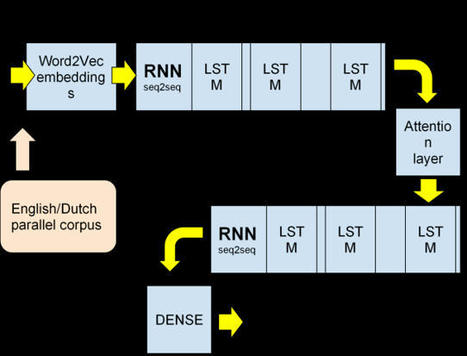
In the previous article, we built a deep learning-based model for automatic translation from English to Russian. In this article, we’ll train and test this model. Here we'll create a Keras tokenizer that will build an internal vocabulary out of the words found in the parallel corpus, use a Jupyter notebook to train and test our model, and try running our model with self-attention enabled.
|
|
Scooped by
nrip
|
Google Translate works so well, it often seems like magic. But it’s not magic — it’s deep learning! In this series of articles, we’ll show you how to use deep learning to create an automatic translation system. This series can be viewed as a step-by-step tutorial that helps you understand and build a neuronal machine translation. This series assumes that you are familiar with the concepts of machine learning: model training, supervised learning, neural networks, as well as artificial neurons, layers, and backpropagation. In this article, we’ll examine the tools we'll need to use to build an AI language translator. Multiple frameworks provide APIs for deep learning (DL). The TensorFlow + Keras combination is by far the most popular, but competing frameworks, such as PyTorch, Caffe, and Theano, are also widely used. These frameworks often practice the black box approach to neural networks (NNs) as they perform most of their "magic" without requiring you to code the NN logic. There are other ways to build NNs — for instance, with deep learning compilers. The following table lists the versions of the Python modules we’ll use. All these modules can be explicitly installed using the ==[version] flag at the end of a pip command. For instance: "pip install tensorflow==2.0". The code we're writing should work on any operating system but note that we're using Python 3, so make sure you have it installed. If your system has both Python 2 and Python 3 installed, you'll need to run pip3 instead of pip in the install commands below: module version TensorFlow 2.3.1 Keras 2.1.0 numpy 1.18.1 pandas 1.1.3 word2vec 0.11.1 read the entire article for the list of instructions at https://www.codeproject.com/Articles/5299747/Tools-for-Building-AI-Language-Translation-Systems
|
|
Scooped by
nrip
|
It’s still tough to opt out of Apple and Google’s ecosystems. But some app makers are coming around to the web’s upsides the web-first approach is one that some developers have been rediscovering as discontent with Apple’s and Google’s app stores boils over. Launching with a mobile app just isn’t as essential as it used to be, and according to some developers, it may not be necessary at all. There are new examples emerging which demonstrate how developers are now building Web apps smartly for the mobile and skipping listing in App Stores, demonstrating what a modern, fast web app can do, There’s just one problem with this zeal for web apps: On iOS, Apple doesn’t support several progressive web app features that developers say are necessary to build web apps that offer all the power and usability of a native app. iOS web apps, for instance, can’t deliver notifications, and if you install them on the home screen, they don’t support background audio playback. They also don’t integrate with the Share function in iOS and won’t appear in iOS 14’s App Library section. Android, by contrast, supports most of those features, and even allows websites to include an “Install App” button. Read the original article at https://www.fastcompany.com/90623905/ios-web-apps to see some of the examples which are discussed. Of those 2 of them I personally tried out, liked and started using after reading the article i.e. 1Feed and Wormhole
|









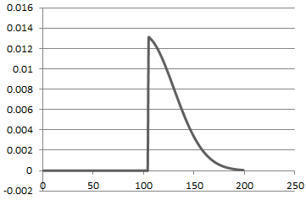

















Algorithms make programs come to life. They make code think and applications feel.
Compression algorithms made digital speech possible years ago. I remember the days when we had all of 16KB to work and we were fitting an RTOS, real time operating system with a vocoder and we would fighting over optimizing bytes over execution time.